El protocolo HTTP
El Protocolo de Transferencia de HiperTexto (Hypertext Transfer Protocol) es un protocolo de red basado en el modelo cliente-servidor para la transmisión de recursos hipervínculados.
HTTP fue propuesto por Tim Berners-Lee para el desarrollo de un sistema global de distribución de información como el World Wide Web.
Tim Berners-Lee ("padre de la Web" a la izquierda) & Vinton Cerf ("padre de la Internet" a la derecha)

Los estándares asociados a HTTP son:
- RFC 1945 (HTTP/1.0, 1996)
- RFC 2616 (HTTP/1.1, 1999)
- RFC 7540 (HTTP/2.0, 2015)
HTTP/2.0 es la versión más reciente de HTTP, pero HTTP/1.1 sería la mayormente usada.
En palabras de Irina Delgado:
La web es comúnmente confundido con el Internet, pero la web sólo es una aplicación más que te permite compartir información que trabaja sobre el internet y no fue hasta la década de los 80′s cuando se vio esta aplicación como un uso comercial. Las páginas web que vemos en nuestros navegadores web constituyen la Web; la red de computadoras interconectadas en el mundo que nos permiten ver estas páginas web constituyen la Internet. "La Internet no es la Web y la Web no es la Internet" - Diferencia entre Internet y Web
En palabras de Gabriela González:
Internet es una red global a gran escala que permite la conexión de millones y millones de dispositivos al mismo tiempo, y que es completamente libre y abierta. La Web es sólo una de las maneras en las que la información puede fluir a través de Internet, es sólo una porción, y aunque es muy grande y la parte más popular, no incluye la totalidad de Internet. - Internet y la web no son lo mismo, te explicamos por qué
Características de HTTP
Se establece sobre la capa de conexión TCP/IP y funciona de la misma forma que otros servicios comunes de entornos UNIX. Un proceso servidor escucha en un puerto TCP (por defecto, el 80) y espera las solicitudes de conexión de los procesos clientes. Una vez que se establece la conexión, el protocolo TCPse encarga de mantener la comunicación y garantizar un intercambio de datos libre de errores.
Se basa en sencillas operaciones de solicitud-respuesta. Un cliente de HTTP establece una conexión con un servidor de HTTP y envía un mensaje con los datos de la solicitud. El servidor de HTTP responde con un mensaje similar, que contiene el estado de la operación y su posible resultado. Todas las operaciones pueden adjuntar un recurso sobre el que actúan; cada recurso es identificado por su URL (Uniform Resource Locator o Localizador de Recursos Uniforme).
Permite la transferencia de recursos multimedia, codificando los archivos binarios en cadenas de caracteres. El contenido de cada recurso intercambiado está identificado por su clasificación MIME (Multipurpose Internet Mail Extensions o Extensiones Multipropósito de Correo de Internet).
Existen ocho verbos (también conocidos como comandos o métodos) que permiten que un cliente de HTTP pueda dialogar con el servidor. Los dos más utilizados serían:
- GET: para obtener un recurso.
- POST: para enviar datos al servidor.
Cada operación HTTP implica una conexión con el servidor, que es liberada al término de la misma. Lo anterior implica que una petición solo puede solicitar un solo recurso.
Con la versión HTTP 1.1 se ha mejorado este procedimiento, permitiendo que una misma conexión se mantenga activa durante un cierto periodo de tiempo, de forma que sea utilizada en sucesivas transacciones. Este mecanismo, denominado HTTP Keep Alive, es empleado por la mayoría de clientes web y servidores web modernos.
No mantiene estado (stateless). Cada petición de un cliente de HTTP a un servidor de HTTP no es influida por las solicitudes anteriores por lo tanto cada petición es una operación totalmente independiente del resto de peticiones.
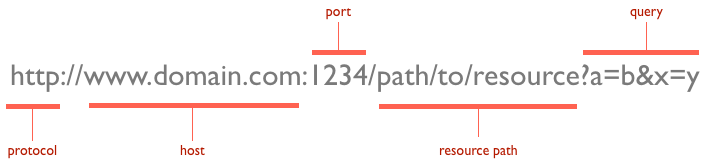
Cada recurso al que se aplican los verbos del protocolo está identificado a través de un URL. Un URL permite identificar el protocolo de red, la ubicación (dirección IP o nombre de host) así como el puerto TCP para solicitar el recurso.
Funcionamiento
Cada vez que un cliente de HTTP realiza una petición a un servidor, se ejecutan los siguientes pasos:
Un usuario accede a un URL, seleccionando un enlace de un documento HTML o introduciéndola directamente en el cliente de HTTP:

Algunos ejemplos de cliente de HTTP son:
El cliente de HTTP interpreta el URL, separando sus diferentes partes: protocolo de red, dirección IP o nombre de host, puerto TCP (opcional) y recurso a solicitar.
Se abre una conexión TCP/IP con el servidor de HTTP al puerto TCP correspondiente, por default el 80.
Se realiza la petición (request). Para ello, se envía el comando necesario (GET, POST, HEAD, etc), la dirección del recurso a solicitar, la versión del protocolo HTTP empleada y un conjunto variable de información que incluye datos sobre las características del navegador así como datos opcionales para el servidor, etc.
El servidor de HTTP devuelve la respuesta (response) al cliente. Consiste en un código de estado y el tipo de dato MIME del recurso entregado, seguido del propio recurso.
Algunos ejemplos de servidores de HTTP son:
- Servidor HTTP Apache: conocido simplemente como servidor apache y parte del famoso acrónimo LAMP (Linux, Apache, MySQL and PHP) al final de la década de 1990.
- Internet Information Services (IIS): por parte de Microsoft y asociado a la plataforma de desarrollo Microsoft.NET.
- Jetty: servidor de HTTP y contenedor de servlets de Java.
- Apache Tomcat: contenedor de servlets de Java. Incluye a Coyote HTTP/1.1 Connector.
- thttpd: Marca ACME (ACME Laboratories)
- Lighttpd.
- Nginx.
- Cherokee
- darkhttpd.
- Hiawatha.
- Monkey HTTP Server.
- ShimmerCat.
- Yaws.
- the bozotic HTTP server.
- lophttpd.
- Merecat.
Se cierra la conexión TCP.
Si no se utiliza el modo HTTP Keep Alive, este proceso se repite para cada acceso del cliente de HTTP al servidor de HTTP.
Mensajes de solicitud y de respuesta
El diálogo con los servidores HTTP se establece a través de mensajes formados por líneas de texto, cada una de las cuales contiene los diferentes comandos y opciones del protocolo. Solo existen dos tipos de mensajes, uno para realizar peticiones (Request message) y otro para devolver la correspondiente respuesta (Response message).
La primera línea del mensaje de solicitud contiene el comando que se solicita al servidor de HTTP, mientras que la primera línea de la respuesta contiene el resultado de la operación identificado por un código numérico que permite conocer el estado de dicha operación. Después aparece, para ambos tipos de mensajes, un conjunto de cabeceras (unas obligatorias y otras opcionales) que condicionan el funcionamiento del protocolo. La separación entre cada línea del mensaje se realiza con un retorno de carro más nueva línea. El final de las cabeceras se indica con una línea en blanco, tras la cual se pueden incluir los datos transportados por el protocolo, por ejemplo, el documento HTML que devuelve un servidor.
Comandos de HTTP
El protocolo HTTP 1.1 consta de los siguientes comandos:
GET: sirve para obtener algún recurso del servidor.
Se utiliza siempre que se pulsa sobre un enlace o se accede directamente a un URL. Como resultado, el servidor de HTTP envía el recurso ubicado en la dirección especificada por dicha URL.
POST: este comando envía datos de información al servidor, normalmente procedentes de un formulario HTML, para que el servidor de HTTP (mediante algún lenguaje de programación) los reciba y procese.
HEAD: es un comando similar a GET pero solicita unicamente la cabecera del recurso.
PUT: almacena un nuevo recurso en el URL especificado. Si la dirección de destino ya contenía un recurso, se considera que se está enviando una versión actualizada del mismo.
DELETE: Elimina el recurso especificado.
TRACE: Realiza un eco de la solicitud recibida para que el cliente de HTTP pueda conocer qué servidores intermedios están añadiendo información o modificando la petición.
OPTIONS: Devuelve los métodos HTTP que soporta el servidor de HTTP. Se suele utilizar para comprobar la funcionalidad de un servidor de HTTP.
CONNECT: Se utiliza en los servidores proxy que puedan establecer un túnel dinámicamente (por ejemplo, un túnel SSL).
GET, POST, PUT y DELETE tiene un uso más en los servicios web (Web Services).
Códigos de estado HTTP
Ante cada solicitud un servidor de HTTP devuelve un código numérico en la primera línea del mensaje de respuesta que informa sobre el resultado de la operación. Estos códigos aparecen en algunos casos en el cliente de HTTP cuando se produce un error:
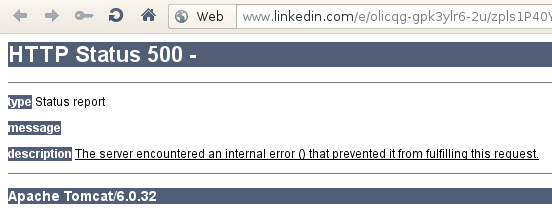
Apache Tomcat en www.linkedin.com:
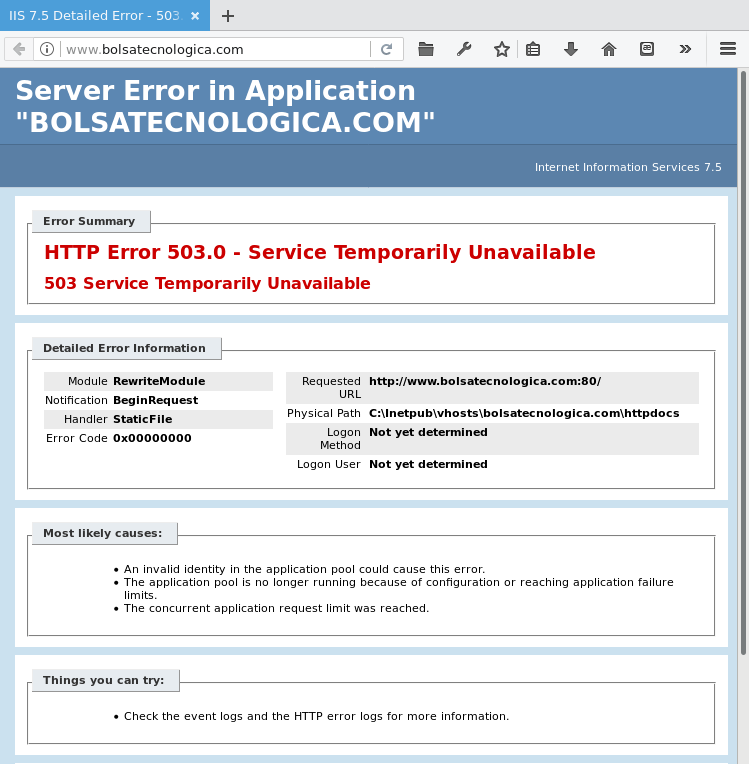
Internet Information Services en www.bolsatecnologica.com:
Los códigos de estado están clasificados en cinco categorías.
- 1xx: Mensajes informativos.
- 2xx: Mensajes de éxito.
- 3xx: Mensajes de redirección. Informan de operaciones complementarias que se deben realizar para finalizar la operación.
- 4xx: Errores del cliente. La solicitud contiene algún error por parte del cliente de HTTP.
- 5xx: Errores del servidor. La respuesta contiene algún error por parte del servidor de HTTP.
Para mayor información revisa los códigos de estado de HTTP.
Muestras
Internet Explorer y Servidor HTTP Apache:
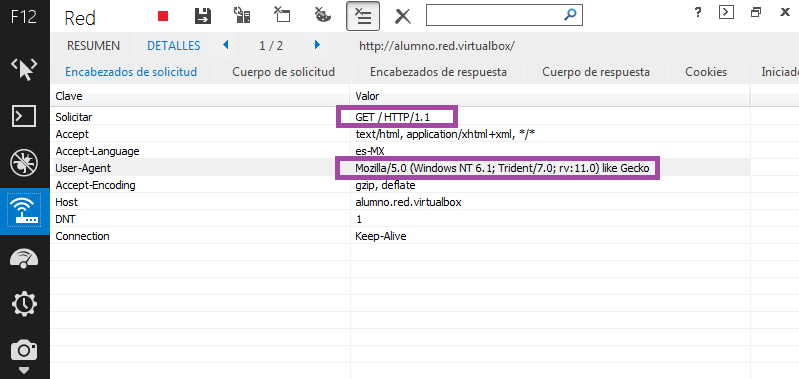
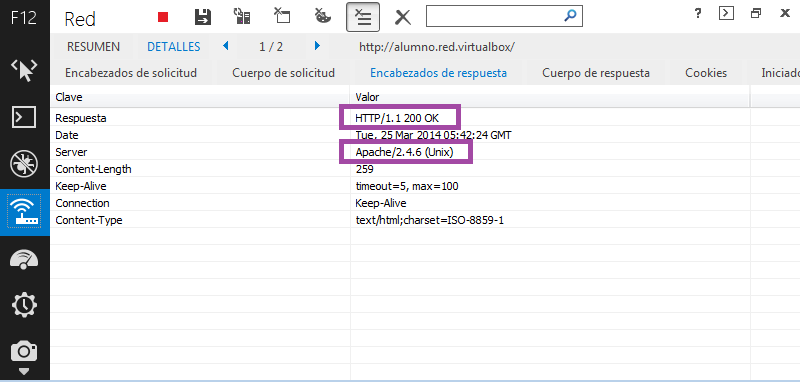
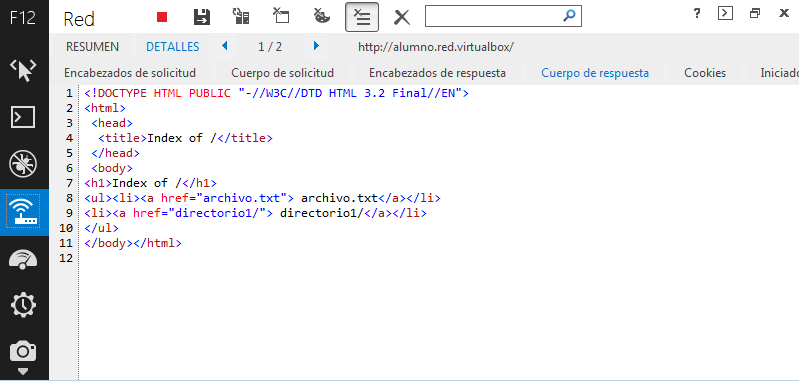
Mozilla Firefox y Servidor HTTP Apache:
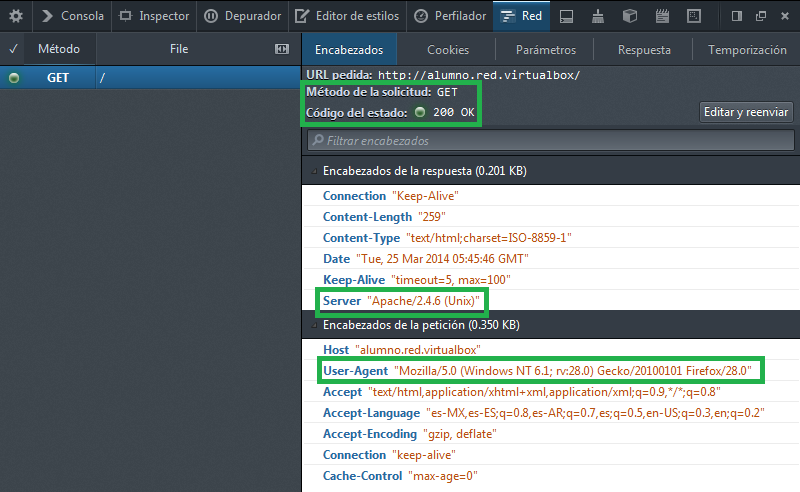
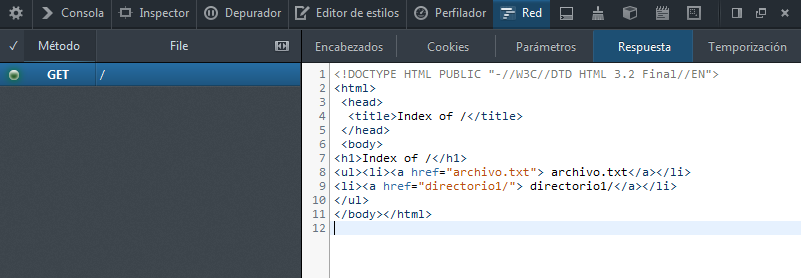
Google Chrome y Servidor HTTP Apache:
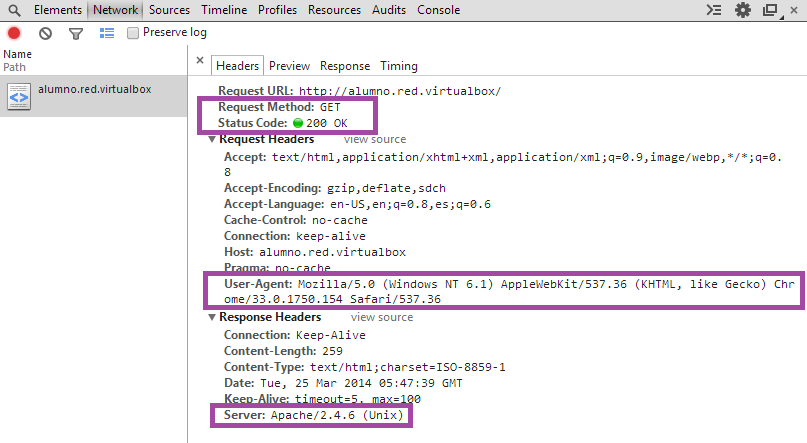
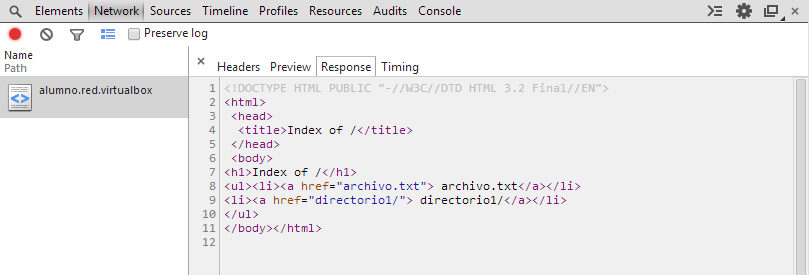
Lecturas
World Wide Web en la Wikipedia
Hiperenlace en la Wikipedia
Protocolo de Transferencia de HiperTexto (HTTP) en la Wikipedia
Multipurpose Internet Mail Extensions (MIME) en la Wikipedia
Localizador de recursos uniforme (URL) e Identificador de recursos uniforme en la Wikipedia
Evolución de la Web [PDF] [copia] Por Pablo E. Lozada Y.
Exceptuando los temás a partir de la Web Semántica (página 23).
M2108 - Desarrollo de aplicaciones web, Marzo 2004 por Carles Mateu.
De su documento en formato PDF lee solo el capítulo 1 (Introducción a las aplicaciones web) y la sección 2.1 (Conceptos básicos del servidor web).
Protocolo HTTP [PDF] [copia] Por J. Javier Samper y Vicente Cavero Millán.
Exceptuando los temás a partir de los Elementos Avanzados (página 14).
Protocolo HTTP [PDF] [copia] Por Francisco Prieto Donate
- HTTP y aplicaciones web [PDF] [copia] Por Otto Colomina Pardo, Pilar Arques Corrales y Javier Montoyo Bojo
Videos
Internet y la Web por iDESWEB UA
Introducción a Internet y a la Web por Universidad Politécnica de Madrid